
Microsoft offers some advice and guidance on different farm configurations, however, starting with SharePoint 2013 there seems to be a preoccupation with the number of VM hosts that are involved and how the virtual servers are deployed across these servers. Certainly managing the distribution of virtual servers across your physical virtual infrastructure is important, however, this adds a layer of complexity in trying to understand the number of virtual servers which need to be created which can be safely deferred until you’ve determined the virtual servers and the resources they need.
The more difficult challenge I find with my clients is how many virtual servers are needed for a fully functional fault tolerant environment. The Microsoft answers are incomplete because they fail to take into account the Office Web Applications and Azure Workflow Service infrastructures which are required to fully utilize SharePoint. The diagrams provided on the posters from Microsoft simply don’t make it clear how these pieces fit together and the number of virtual servers that you’ll need. My goal in this post is to clarify ambiguity about the number of virtual servers, to provide a model for a minimally fault tolerant environment, and to create a plan that can be expanded for scalability.
Fault Tolerance or Scalability
Before we begin it’s important to realize that with most of my clients we don’t end up with scalability concerns nearly as quickly as we identify fault tolerance as a goal. Even organizations with a few thousand employees are unlikely to need more than one front end web server from a scalability perspective. However, organizations of less than a thousand employees quickly find that SharePoint is a critical service offering that needs fault tolerance to support the service level agreements demanded by their organization.
With my larger clients we have scalability conversations – particularly as it relates to the search infrastructure – however, this is the secondary conversation after we cover fault tolerance. The model here is easily expandable based on scalability needs, but that’s not the focus.
Separation of Duties and Missing Pieces
Conceptually SharePoint has two types of farm-member servers – web front ends and application servers. The distinction between the two is largely which parts of the SharePoint infrastructure are running on each. Conceptually having them separate makes the conversations easier. This conceptual framework – between servers directly responding to users and servers responsible for services – is a well-established approach for delivering web applications. As a typical web application would, SharePoint has a set of non-farm member servers which are responsible for database services. On the surface this looks like a SharePoint installation would require only six virtual servers – two web front ends, two application servers, and two database servers. In fact, this was the configuration required for SharePoint 2010 and one could easily make the mistake that this is the right answer for SharePoint 2013 as well. However, there are two wrenches in this thinking.
The first missing piece is that Office Web Applications which used to be installed directly on the SharePoint farm can no longer be installed on a SharePoint farm member server. Office Web Applications are used by SharePoint to render previews of documents in search as well as allowing users to transparently work with documents even if they don’t have the full Office application suite installed on their PC. Making this service fault tolerant requires another pair of virtual servers for Office Web Application fault tolerance – bringing our number of virtual servers to eight.

The second missing piece is Azure Workflow Services – the platform on which the SharePoint 2013 workflow engine is built. Typically this wouldn’t be a big deal — you would install these components on the application servers just like the host of other services that SharePoint offers directly. However, the challenge here is that Azure Workflow Services are built upon the Azure Service Bus and the Azure Service Bus requires three servers – not two servers – to be minimally fault tolerant. The net impact of this is that you have to either have three servers for running workflow or you need to scale out one of the existing layers to three servers. So a farm with Workflow on its own looks something like this:
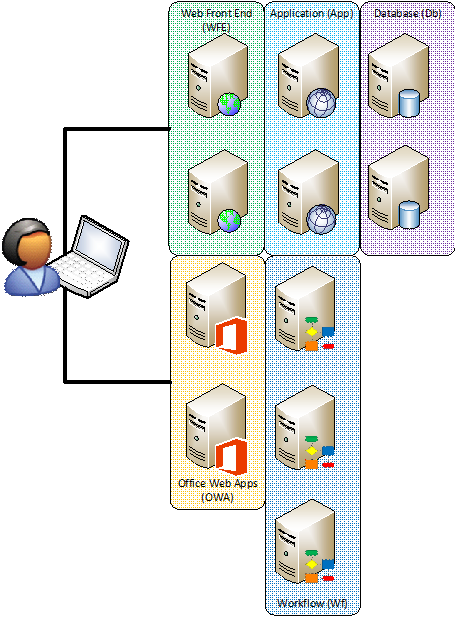
Nine or Eleven Servers
Deciding whether to have nine big servers or eight big servers and three tiny servers for workflow is based largely on preference. A virtual server running SharePoint is recommended to have 12GB of RAM and four CPUs. A workflow server, by contrast, can be tiny. 4GB of RAM is plenty for a workflow server. So you can add another server with 12GB of RAM or three smaller servers with 4GB of RAM each for workflow. If you stacked the Workflow services on top of application servers it would look something like this:
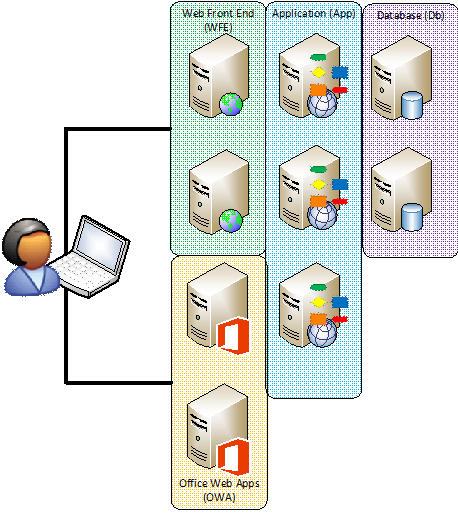
There’s some discussion about the best place to put the workflow services – whether they should be deployed with the application servers because the workload is more similar to the workloads of application servers. That is, that application servers typically don’t respond to time-sensitive requests from the user and are more frequently used to handle back end processing where it’s acceptable for a short delay – as is the case with workflow. However, the counter argument is that having extra capacity in the web front ends is more advantageous in most environments than having an additional application server. This is a decision that can be made on a case-by-case basis based on the workload of the farm.
However, I frequently recommend that clients run workflow on separate servers rather than scaling out the application or web front end layer of the farm due to separation of duties concerns. Most organizations prefer to keep distinct services on different tiers of hardware when doing so doesn’t unnecessarily increase complexity. For most environments, the net effective use of resources is very similar.
Scalability Again
Either of the above approaches to building a farm can be scaled out as needed to add additional capacity to the Office Web Applications, Search services on the application tier, or even additional database instances to support larger database needs. Those scaling decisions are based on stress points in the infrastructure. For instance, if none of the clients will have Office installed, it may be necessary to scale out the Office Web Applications. If you’re indexing a large amount of content on file shares it may be necessary to expand out the application tier to support greater search needs.
By beginning the planning by first looking into the fault tolerance requirements, it’s easier to add additional servers to meet scalability requirements. However, the performance of your virtual host infrastructure is an important consideration in scalability.
Virtual Host Infrastructure
The performance of virtual machines across different virtualization farms is vastly different based on the architecture of the virtualization environment. So a small number of servers on a well-functioning infrastructure can easily out perform more servers on poor performing virtualization environments. The typical concerns for performance including processing capabilities (CPU), memory availability (particularly overcommitted memory utilization), network (sufficient network bandwidth), and disk performance are all important considerations.
In addition to the fault tolerance considerations for the number and type of virtual servers, it’s also important to ensure that the virtual servers are spread out across at least two different physical host servers to ensure that a failure of the virtualization host won’t bring down the environment.
When considering scalability of a SharePoint farm, in a virtual environment it’s key to understand what the performance of the virtualization environment is – and will be.
Conclusion
While the appearance is that SharePoint can be installed in a fault tolerant configuration in as few as six virtual servers, this isn’t the case when the farm is intended to be fully functional. For a minimally fault tolerant configuration, not considering scalability concerns, requires at a minimum nine servers and often as many as eleven.
No comment yet, add your voice below!