
We’re here to mourn the death of many a workflow instance at the hands of SharePoint’s HTTP throttling. Except it’s not SharePoint’s throttling that is the true killer. SharePoint’s just the accomplice in this crazy dance that will get your workflows killed. Though it’s possible to protect your workflow instances from being throttled to death, it isn’t as easy as it might seem. In this post, we’ll talk about what happens every day and then what strategies you can use to protect your workflow.
Request Throttling
Before we can explain how a flow gets throttled to death, we first must understand a bit about throttling. Web servers are under constant assault from well-intended users, the code written by bumbling idiot developers (of which occasionally I am one), and malicious people. One of their defenses is to respond with “I’m too busy right now, come back later.” This comes back as the code HTTP status code 429. Sometimes these responses are kinder and will indicate when the person should come back. “Hey, I should be able to take care of that request for you after seven seconds” tells the program when it should retry the request – and here’s the kicker – expect that it will be able to be serviced.
The problem is that, when you’re dealing with so many different users and so many variables, it’s sometimes difficult to predict when the server will be willing or able to service a request.
Automatic Retries
Because a server may respond with a 429, most programs know to retry the request. The strategies vary but the default answer is an exponential interval. The first time you get a 429, you stop for a period of time – say four seconds – and then each time you retry, you square the interval. So, four seconds becomes sixteen on the second retry, and 256 seconds on the second interval. Flow allows you to follow the default policy, which is described as exponential, or explicitly set the interval to exponential. To do this, click the ellipsis at the right of the action and select Settings.
The action’s space in the flow will change to the settings view, where you can explicitly set the retry policy to exponential – which will further change the view to provide spaces for a maximum retry count, an interval, minimum interval, and maximum interval.
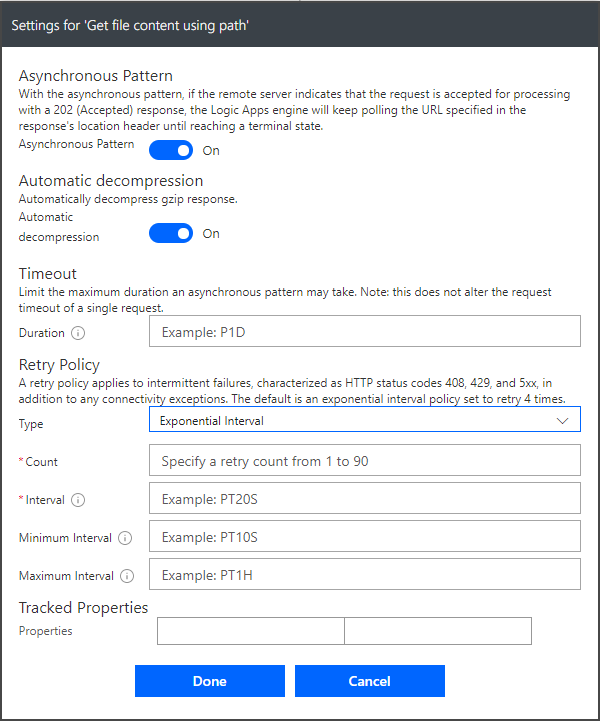

The default settings, however, are supposed to do exponential waiting on retries and four retries. So that seems like a good place to start. The default is implemented as one try plus three retries. That is how they get to four retries.
Retry Schedule Conflicts
What happens when there is a conflict between the provided retry schedule and what the server responded with as a part of its 429 response? The good news is that Flow will use the larger of the two numbers. In theory, at least, you’ll never hit a retry more than once or twice. Sure, the server could make a mistake with its guidance once but surely not twice. Unfortunately, that’s not always the case. Sometimes the response from the server – and the default exponential interval – will be too small, and you’ll exhaust the three retries and end up failing your request. This typically happens when you have multiple flows running at the same time.
Parallelism
Any given Flow may not be making that many requests, but what happens when there are many Flow instances running at the same time? If you do work on a queue that information is dropped into, you can’t necessarily control how many items will come in at the same time. With the scalability of the Flow platform, what’s to stop you from running hundreds or thousands of Flows at the same time – against the same poor server that’s just trying to cope?
If you have 100 Flows all starting in a relatively short time talking to the same back end server, it may be getting thousands of requests from Flow every minute. Even if each Flow is told to retry later, even the server telling the consumer to retry later may cause the server to need to push off work even further. The result is that every Flow gets throttled to death – until so few remain that they can be handled inside of the capacity of the server.
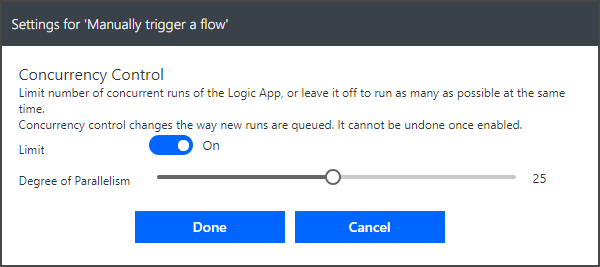
Luckily, Flow offers a technique for limiting the number of active flows at any time. This can be done by going to the ellipsis and then Settings for the trigger. This changes the trigger to its settings display, which allows you to limit the number of concurrent Flow instances – or the degree of parallelism.
SharePoint Request Throttling
Generic request throttling is fine but how does my favorite server – SharePoint – do it? Well, the answer isn’t clear. Microsoft published an article “Avoid getting throttled or blocked in SharePoint Online“, which says that they won’t publish the rules – because they’re changing them.
At the same time, they make clear that some of the criteria being used to manage the workflow are things like user agents, accounts, and App IDs. However, when it comes to Flow, we have some limitations.
Flows always run as the user that created the Flow – not as the user initiating the request. So, from the point of view of SharePoint, one user is making all the requests – and they’re making them from the same application, Flow. This makes Flows a high target for throttling, even when you consider it’s a well-known and well-trusted application.
It turns out there’s more to it than that. There’s an interface layer that the connectors – including the connector to SharePoint – use.
Connectors and Infrastructure
Many of Microsoft’s new offerings like Flow, PowerApps, and PowerBI need access to the same service data inside of multiple tenants. As a result, the connectors use a common architecture that allows multiple services to interact with Microsoft’s online service offerings. This architecture has its own throttling built in. It’s designed to protect the back-end services and has its own rules for throttling requests that’s more aware of the uniqueness of each of the fixed number of Microsoft internal consumers.
One of the things that this infrastructure can use to manage throttling is the connection to the service. In the first figure, you’ll notice two connections in the settings menu – with the same identity. This is one way that you can help the infrastructure avoid throttling you.
Multiple Connections
When there aren’t many things to differentiate requests on, the connection is one. It’s got its own identifier. Because of that, it’s easy for the back end to see which connection a request is associated with – and throttle too many requests from a single connection. Thus, if you want to help your Flow avoid getting throttled, you can make multiple connections to the same data source. This allows your requests to get spread across different thresholds and for more to get through.
The Fingerprints Match
For my case, the Flows were getting throttled not by SharePoint directly but through the infrastructure hub. I set the maximum degree of parallelism and assigned every action in the flow to a different connection, but it wasn’t enough. I didn’t set the retry settings manually, and the default settings continued to allow my poor Flows to be throttled to death by the infrastructure.
In the end, to spare more Flows from being throttled, we moved some of the data to Azure SQL. However, we saved many Flows just by adjusting the retry strategy and concurrency and creating multiple connections.
No comment yet, add your voice below!