
Implementing Kerberos is frequently considered painful by IT Professionals. It seems like there’s some magic incantation that has to be said over the network for things to work correctly. However, the components are relatively straight forward. In this post I’m going to walk through Kerberos setup front to back including delegation, how to get it working, and what doesn’t work. My goal is to distil a great number of blog posts with half-collected information and make it all fit together so you can implement Kerberos step by step.
Some folks talk about Kerberos as resolving the double-hop problem – though that’s relatively old terminology which is really talking about the fact that you’re not allowed to use the client’s NTLM credentials to access another source. Kerberos allows you to use pass-through authentication so the user’s credentials can be used for backend services – particularly for access to SQL data.
This post applies equally to SharePoint 2010 and SharePoint 2013. The biggest change is that in 2010 you could do unconstrained Kerberos delegation (explained later) if you continued to use Windows Authentication. Since 2013 practically eliminates this option and strongly encourages the use of claims, you can no longer do unconstrained Kerberos delegation and must implement constrained delegation which is a little bit more challenging to setup. Let’s start with getting users to be able to use Kerberos to login to the SharePoint site.
SharePoint Login via Kerberos
Getting Kerberos to login to the SharePoint site is the first step. This involves only two major steps. First, getting the service principle name correct in Active Directory. Second, you must configure SharePoint to accept Kerberos authentication. Let’s look at each of these in turn.
Service Principle Names for Kerberos
Kerberos is old in computer terms having come out of work at MIT and having been used for a long time. At its core, Kerberos requires mutual authentication. That is the server must identify itself to the client and the client identifies itself to the server. In Windows much of this is handled automatically as computers are automatically registered with their names in active directory. The problem occurs when a computer needs to host a site that’s not the same as its computer name. For instance, when www.leadinglambs.com is hosted on SP2013-DC and no changes have been made, a client wouldn’t allow Kerberos authentication because the name of the resource being accessed (www.leadinglambs.com) doesn’t match the name of the server providing the resource. This is fundamentally the same sort of protection that is used in SSL – the name of the certificate must match the name the client is using to access the resource. The solution to getting the names right is to setup a service principle name.
One added complication is that the service account (application pool account) and not the computer is the account in active directory which gets enabled for the URL. So your service account (say sp.svc) is what you register the target name to. Before we can set the name we need to understand the full service principle name and not just the URL component of it and that leads us to services and protocols.
Service classes and Protocols
One common mistake is to believe that you prefix the URL in a service principle name with the actual protocol that is being used. This isn’t correct. For instance, in SharePoint 2013 most URLs are going to be SSL or HTTPS URLs and yet the service principle name will start with HTTP/. The reason for this is that service principle names aren’t using literal network protocols. They’re service classes. As a result adding with HTTP/ enables the account to respond to both HTTP and HTTPs. The two service classes that are the most interesting to most folks are HTTP and MSSQLSvc which is used for SQL Server connections.
Port Shifting
Before leaving how to form SPNs, it’s important to talk about what happens when you port shift services – that is you make them available on a non-standard port. This isn’t a problem for Kerberos but you have to append a comma and the port number to the end of the SPN. So for example if you have www.leadinglambs.com running HTTPS on a non-standard port of 4443 (instead of 443) you’ll need an SPN of HTTP/www.leadinglambs.com,4443
Set SPN
The tool that you use for registering the SPN in AD is SETSPN and it comes on most servers – worst case you can run it from a domain controller which will surely have it. The format of the command you want is SETSPN –S <SPN> <account>. In our www.leadinglambs.com web site example on a standard port on the service account SP.SVC would look like this:
SETSPN –S HTTP/www.leadinglambs.com sp.svc
You may want to do a –L and the account name (SETSPN –L SP.SVC) to list out all the service principle names on the account to make sure you got it right after you’ve done the addition. Also, we recommend –S instead of the older –A because –S will ensure there are no duplicates. If you have two account registered with the same SPN – you won’t be able to authenticate via Kerberos to that service.

Enabling SharePoint for Kerberos
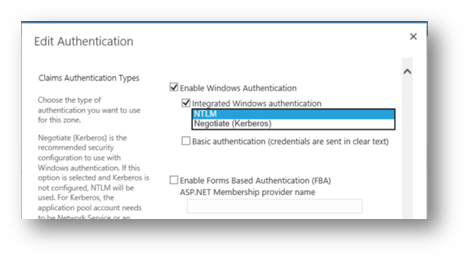
Enabling SharePoint to accept Kerberos for authentication is straight forward. You go into Central Administration, select Manage Web Applications, click in the whitespace to the right of the web application name you want and in the ribbon click the Authentication Providers option. From the Authentication providers dialog click on the default zone and in the Edit Authentication dialog select the drop down under Integrated Windows authentication and select Negotiate (Kerberos). Next scroll down and click the Save button.
Now it’s time to test it. For that you’ll want to use the awesome and free Fiddler (www.fiddlertool.com). I won’t go into the details of how to setup Fiddler so it can decrypt HTTPS traffic. There are plenty of walkthroughs on how to do that. Once you have Fiddler running try to login to the site. The initial request will get a HTTP 401 response from the server (unauthorized). The browser will respond with authentication and you’ll see something like the following in the request:
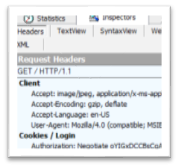
This indicates that the browser authenticated with Kerberos.
Delegating Authentication via Kerberos
While logging in via Kerberos is a good start, you still can’t use the user’s credentials to access other resources until the account for the machine in Active Directory and the service account are trusted for delegation. There are two approaches to delegation – unconstrained and constrained. On the surface it would seem like unconstrained would be a better approach (less constraining). However, unfortunately in a claims mode implementation will require constrained delegation. However, let’s look at both options.
Unconstrained Delegation
When a user logs in with Kerberos it’s possible to trust a computer and a service account and use their Kerberos identity with back end resources – when the computer and service account are trusted for unconstrained delegation. With this setting they’ll be able to go to any backend service in the network using those credentials. This was the method we used in SharePoint 2007 and for SharePoint 2010 when not using claims. However, when we’re using claims we really don’t have a Kerberos login to pass along. The user logged into the web server with Kerberos and we generated a claims token from there on out we’ve been using the claims token to access local resources. So when we want to access remote resources we can’t just delegate the Kerberos ticket because we don’t have it any longer.
Behind the scenes SharePoint has been using the Claims to Windows Token Service to get a Windows token for a given user from the user’s identity claim. This works well for on-box resources but it’s not valid for remote resources when using unconstrained delegation because it didn’t originate from a user Kerberos login directly – claims is in the middle. What we need to be able to do is to do a protocol transition. That is we need to be able to use our claims based authentication protocol and transition to a Kerberos login which we pass along. (I’m purposefully avoiding the detailed technical language of Kerberos about Ticket Granting Tickets, etc., to minimize the complexity of the discussion.)
Constrained Delegation
Constrained delegation works like unconstrained delegation in that the service can reuse the credentials of the user except the credentials can only be used for prespecified services. When delegation is setup for the computer and service account the administrator specifies what services can be delegated to. Additionally, and importantly as previously mentioned, it’s possible to do protocol transition. This is essential. Constrained delegation requires that you specify the allowed service endpoints. Let’s looking at setting up constrained delegation in Active Directory Users and Computers.
Setting Delegation
Before setting up delegation the first step is to make sure that the service account used for the service that you want to be able to delegate has to have its service principle name setup too. So if you want to delegate to SQL server running on the default instance on the SP2013-SQ box running on the service account SQ.SVC you need to you’re the SETSPN command:
SETSPN –s MSSQLSvc/SP2013-SQ SQ.SVC
Once the service principle name for the service is setup, setting up delegation isn’t difficult. It’s a matter of bringing up the computer account and the service account and changing the settings on the delegation tab. Let’s start with the delegation tab of the computer account. Find the computer account (you can use Right-Click Find… if you want) and select properties then select the Delegation tab. It should look like this:
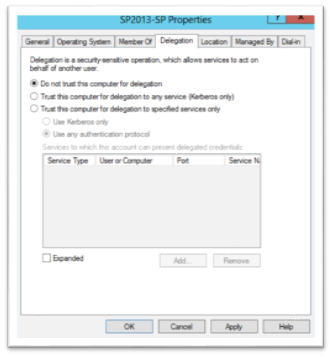
Click the Trust this computer for delegation to specified services only (which is constrained delegation). Then click the Use any authentication protocol radio button if it’s not already selected. Then Click the Add button to add the services that this computer can delegate to. The Add services dialog will appear like this:
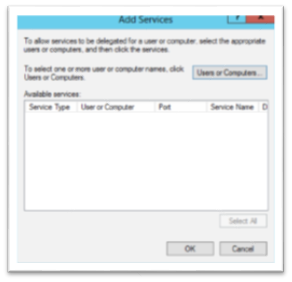
Next Click the Users or Computers… button. Enter the name for the service account for the SQL server that you want to delegate to and click OK. The list of SPNs associated with the account will appear and you can click the services you want or click the Select All button – the dialog will look something like:
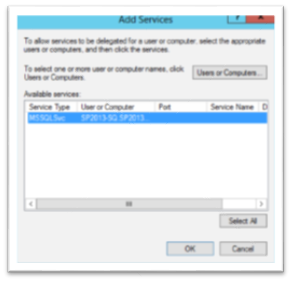
Click OK to close the Add Services dialog then OK again to close the computer properties. Find the SharePoint service account and do the same procedure for it. Note that if you haven’t already assigned the service principle name to the SharePoint service account the Delegation tab won’t even show up in the properties for the user – so you’ll need to make sure that you associate the SPN for the SharePoint web site first.
Special Considerations
There are some special considerations that can create problems with Kerberos that it’s worth mentioning here:
- DNS CNAME – Kerberos doesn’t like DNS CNAMEs. If you have a CNAME setup instead of an A record for resolving the name of the server, you’ll want to setup the A record.
-
Sensitive Accounts – There’s a setting in the user account on the account tab which says “Account is sensitive and cannot be delegated” Accounts with this setting checked cannot be delegated and no delegation settings on the computer or service account will allow the account to be delegated. It looks like this:
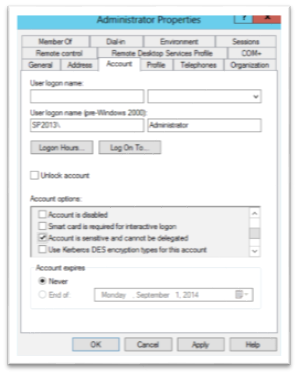
- Impersonate Client – The service account has to have one more right – which is set in the security policy for the computer. That is it needs the right ‘Impersonate a client after authentication.’ This right is normally granted through membership in the IIS_USRS local group. This group is – by default – assigned this right.
Troubleshooting
One of the hardest things with Kerberos is that testing your setup is very difficult and logging for what is wrong is effectively non-existent. However, there is a way that you can use out-of-the-box functionality to see if Kerberos delegation is working. You can setup an external content type with SharePoint Designer. Lightning Tools have step-by-step instructions at http://lightningtools.com/bcs/creating-an-external-content-type-with-sharepoint-designer-2013/ This will give you a quick way to test to see if your setup functions before using other tools.
One other additional troubleshooting idea that you may need to look into is enabling LSA Loopback if you’re testing on the server locally. You can find out more about how to set this up in the MS KB article 896861.
Additional Resources
If you’re interested in more background on this topic you can read the Microsoft provided Configure Kerberos authentication for SharePoint 2010 Products.
1 Comment
for those with on-prem (which should be everyone interested in this article), we released a WSP with custom health analyzers to detect kerberos problems. Download from codeplex at : http://sdssharepointlibrary.codeplex.com/releases/view/92022