
The topic of the week appears to be the difference between the two Search Centers in SharePoint. One search center, Search Center Lite — which shows up in the user interface as Search Center, is created by default for you if create a Collaboration Portal. (It’s on /search.) The other search center, Search Center with Tabs, only shows up if you activate the Office SharePoint Server Standard Site Collection features (See below)

Once you’ve activated the feature your create site page will include the full list of templates including: Document Center, Records Center, Personalization Site, Site Directory, Report Center, Search Center with Tabs, and Search Center (See below)
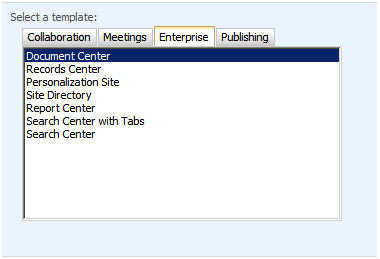

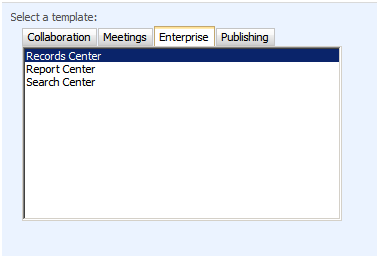
If your create site only has Records Center, Report Center, and Search center — you don’t have the feature activated (see below)
So what’s the big deal? The differences aren’t that big, are they? The standard search center (Search Center Lite) shows:

Where the Search Center with Tabs shows:

Basically tabs. Who cares? Well if you have a set of complex customizations and want people to be able to search in different ways — then you care. Search Center with Tabs uses the publishing features (WCM) in SharePoint to allow you to create your own pages with different search configurations on them.
4 Comments
I activated the feature in my default created Publishing Portal but still do not have the search centers…?
You need to remove the template restrictions. In Site Actions – Site Settings – Modify All Site Settings – Look and Feel – Page Layouts and Site Templates
You’re probably restricted to only the publishing site.
Rob, if a search center has already been created without tabs, is there any way to change it so that it has tabs?
Thanks
Dean
Unfortunately, no. They are different site definitions.