Data Driven Apps – Flattening the Object with PowerApps, Flow, and SharePoint
The scenario we started to explore in Data Driven Apps – Early and Late Binding with PowerApps, Flow, and SharePoint was one of a test engine: we had tests in which we didn’t want to have to code every question as its own form – or even two different tests with two different applications. We left the problem with a set of rows in the table that each represented a separate answer to a question.
The User Experience
The need for flattening these multiple rows into a single record is to make it easier for users to work with. It’s not easy in the user tools – like Excel – to collect a series of rows and to generate an aggregate score. It’s easier to score a single record that has columns for the individual questions and then score that one record.
That’s OK, but the question becomes how do we take something that’s in a series of rows and collapse it into a single record using PowerApps, Flow, and SharePoint? The answer turns out to be a bit of JSON and a SharePoint HTTP request.
JSON
JavaScript Object Notation (JSON) is a way of representing a complex object, much like we used to use XML to represent complex object graphs. Using JSON, we can get one large string that contains the information in multiple rows. From our PowerApp, we can emit one large and complex JSON that contains the information for the test taker and for all the questions they answered.
This creates one item – but it doesn’t make it any easier for the user to process the values. For that, we’ll need to use Flow to transform the data.
We can write this JSON into a staging area in SharePoint and attach a Flow to the list, so any time a row is changed, the Flow is triggered. The Flow can then process the item, create the properly formatted row, and delete the item that triggered the event.
The SharePoint HTTP Request
The power to do this transformation comes from the ability for Flow to call SharePoint’s HTTP endpoints to perform operations. While most of the time, Flows use the built-in actions, the “Send an HTTP request to SharePoint” can be used to send an arbitrary (therefore late-binding) request to SharePoint to take an action. In this case, we’ll use it to put an item into a list. This request looks something like this when completed:
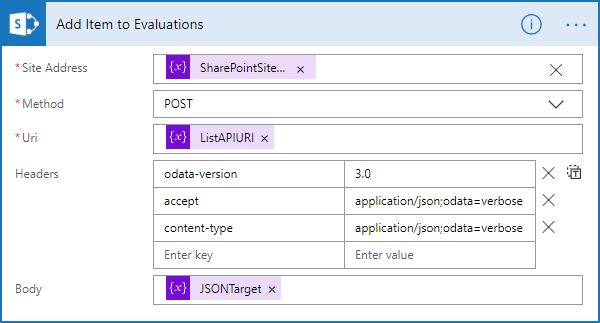
You’ll notice a few things here. First, it requires the SharePoint site URL. (Which you can get by following the instructions in this post.) In this example, the value comes from the SharePointSiteURL variable.
The next thing you’ll notice is that we’re using the HTTP method POST, because we’re adding a new item. URI (the endpoint we want to call) is coming from the variable ListAPIURI, which is being set to:
_api/web/lists/GetByTitle(‘Evaluations’)/items
The title of the list we want to put the item into is ‘Evaluations’, thus the URL. It’s possible to refer to the endpoint a few different ways, including by the list’s GUID, but most of the time accessing the list by title works well, because it’s readable.
The next configuration is to set the headers, which are essential to making this work. You can see that odata-version is set to 3.0, and both accept and content-type are set to application/json;odata=verbose.
Finally, we have the JSON, which represents the item. This is largely a collection of the internal field names from SharePoint – but it has one challenging, additional field that’s required.
__metadata
In addition to the internal fields you want to set values to, you must also set an item “__metadata” to the collection of { “type”: “SP.Data.ListItem” } – unless you’re using SharePoint content types. In that case, you’ll have to figure out what the API is referring to the content type as. We’ll cover that in the next post.
Internal Names of Fields
For the most part, we don’t pay much attention to the internal name of the field. It’s noise that SharePoint uses to handle its business. However, when you create a field, an internal name is created as the name of the field you provide with special characters encoded. Mostly people use spaces when they’re creating names, so “My Field” creates an internal name of My_x0020_Field. You can determine the field’s internal name by looking in the URL when you’re editing the field. The name parameter will be the field’s internal name. (With one exception: if you used a period in the name, it won’t show as encoded in the URL but will be encoded in the name as _x002e_)
Processing the Questions
To get the JSON to send to SharePoint, we need to have three segments that we assemble. There’s the initial or starting point with the __metadata value, there’s a middle with our questions, and there’s an ending, which closes the JSON.
To make the construction easy, we’ll use the Compose data operation action to create a string and put it in a variable. The initial segment we’ll set and then assign to the variable (Set Variable). For the other two segments, we’ll use the Append to string variable action. The result will be a variable with the entire JSON we need.
So, the start looks something like:

After this, we can set a specific field that we want to set. Once this action is done, we use its output to set to our end variable, like this:
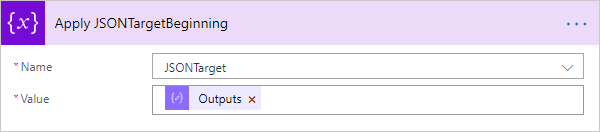
Now we get to the heart of the matter with JSON Parsing that we’ll use to do the flattening.
JSON Parsing
There’s a Data Operation called Parse JSON that allows us to parse JSON into records that we can process in a loop. We add this item, and then, generally, we click the ‘Use sample payload to generate schema’ to allow us to create a schema from the JSON. Flow uses this to parse the JSON into the values we can use. After pasting JSON in and allowing the action to create the schema, it should look something like:
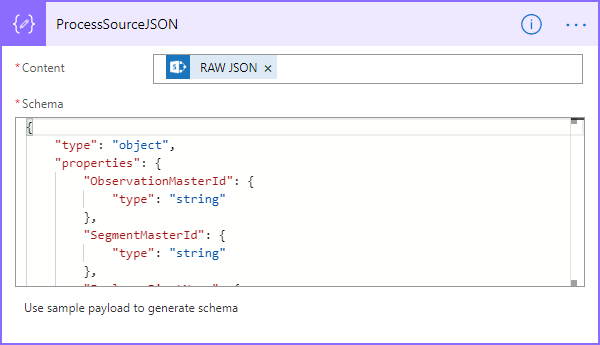
Next, we can use a loop and use the questions variable from the parse operation as our looping variable and move directly into parsing the inner JSON for the question.
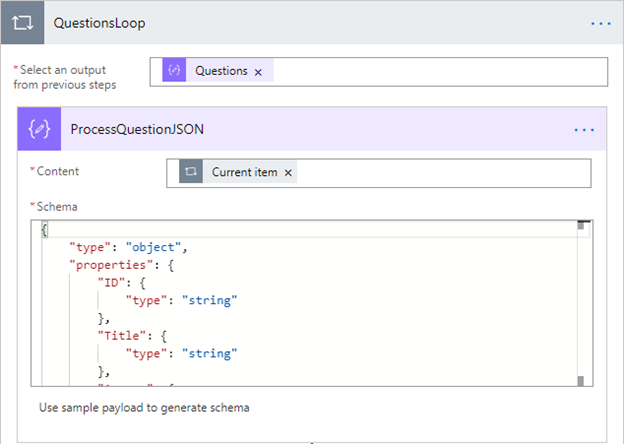
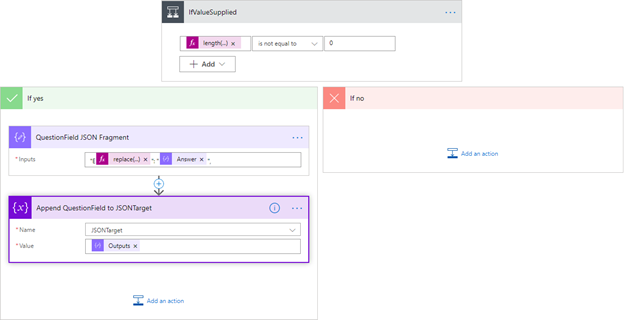
From here, we’ve got our answer, but it’s worth making one check. If, for some reason, they didn’t answer a question, we’ll create a problem, so we do a check with a condition:
length(body(‘ProcessQuestionJSON’)?[‘Answer’])
If this doesn’t make sense, you may want to check out my quick expression guide, but the short version is that it’s checking to make sure the answer has something in it.
If there is something in the answer, we create a fragment for the field with another compose. In our case, we prefixed numeric question numbers with an E. Because the questions also had periods in them, we had to replace the period with _x002e_. The fragment ends with a comma, getting us ready for the next item. The fragment is then appended to the JSON target.
The Closing
We’re almost done. We just need to add an end. Here, because we ended with a comma before, we need to just include at least one field and the closing for our JSON. In our case, we have an ObservationMasterID that we use – but it can literally be any field.

This just gets appended, and then we call our SharePoint HTTP that we started with, and we get an item in our list with all our questions flattened into the record.